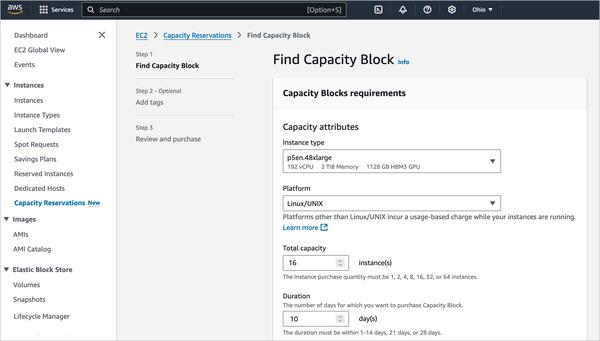
Google에서 Gemma에 초점을 맞춘 대규모 언어 모델 미세 조정에 대한 블로그 게시물을 게시했습니다. 이 기사에서는 데이터 세트 준비부터 시작하여 명령어 조정 모델 미세 조정에 이르기까지 프로세스 전체를 간략하게 설명합니다.
특히 흥미로웠던 점은 데이터 준비와 하이퍼파라미터 최적화의 중요성을 강조한 부분입니다. 이러한 측면은 모델의 성능에 큰 영향을 미칠 수 있으므로 신중하게 고려해야 합니다.
제가 업무에서 자주 접하는 과제 중 하나는 챗봇이 미묘한 뉘앙스를 이해하고 복잡한 대화를 처리하며 정확한 응답을 제공하도록 하는 것입니다. 이 블로그 게시물에서 설명하는 접근 방식은 이 문제에 대한 유망한 해결책을 제시하는 듯합니다.
하이퍼파라미터 조정 프로세스에 대해 자세히 알아보고 싶습니다. 예를 들어 구체적으로 어떤 매개변수를 조정했으며 최적의 값은 어떻게 결정했는지 궁금합니다. 이러한 측면에 대한 심층적인 논의는 매우 유용할 것입니다.
전반적으로 이 블로그 게시물은 매우 유익하며 대규모 언어 모델 미세 조정에 대한 유용한 개요를 제공한다고 생각합니다. 이 정보는 챗봇이나 기타 언어 기반 애플리케이션을 빌드하려는 모든 사람에게 귀중할 것입니다.