Amazon은 머신 러닝(ML) 교육 및 추론을 위한 가장 강력한 EC2 컴퓨팅 옵션인 새로운 Amazon EC2 Trn2 인스턴스와 Trn2 UltraServers를 출시했습니다. 2세대 AWS Trainium 칩(AWS Trainium2)으로 구동되는 Trn2 인스턴스는 1세대 Trn1 인스턴스보다 4배 빠르고, 메모리 대역폭은 4배, 메모리 용량은 3배 더 큽니다. Trn2 인스턴스는 현재 세대 GPU 기반 EC2 P5e 및 P5en 인스턴스보다 30~40% 향상된 가격 대비 성능을 제공합니다. 각 Trn2 인스턴스는 16개의 Trainium2 칩, 192개의 vCPU, 2TiB의 메모리, 최대 50% 낮은 지연 시간의 3.2Tbps Elastic Fabric Adapter(EFA) v3 네트워크 대역폭을 갖추고 있습니다. 새로운 제품인 Trn2 UltraServers는 최첨단 기반 모델에서 최고의 성능을 제공하기 위해 고대역폭, 저지연 NeuronLink 인터커넥트로 연결된 64개의 Trainium2 칩을 갖추고 있습니다. 이미 수만 개의 Trainium 칩이 Amazon 및 AWS 서비스에 사용되고 있습니다. 예를 들어 80,000개 이상의 AWS Inferentia 및 Trainium1 칩이 최근 프라임 데이에서 Rufus 쇼핑 도우미를 지원했습니다. Trainium2 칩은 Amazon Bedrock에서 Llama 3.1 405B 및 Claude 3.5 Haiku 모델의 지연 시간 최적화 버전을 이미 강화하고 있습니다. Trn2 인스턴스는 미국 동부(오하이오) 리전에서 사용할 수 있으며 ML용 Amazon EC2 용량 블록을 사용하여 예약할 수 있습니다. 개발자는 PyTorch 및 JAX와 같은 프레임워크로 사전 구성된 AWS Deep Learning AMI를 사용할 수 있습니다. 기존 AWS Neuron SDK 앱은 Trn2용으로 다시 컴파일할 수 있습니다. 이 SDK는 JAX, PyTorch, Hugging Face, PyTorch Lightning, NeMo와 같은 라이브러리와 기본적으로 통합되어 있습니다. Neuron에는 NxD 교육 및 NxD 추론을 통한 분산 교육 및 추론 최적화가 포함되어 있으며 OpenXLA를 지원하므로 PyTorch/XLA 및 JAX 개발자는 Neuron의 컴파일러 최적화를 활용할 수 있습니다.
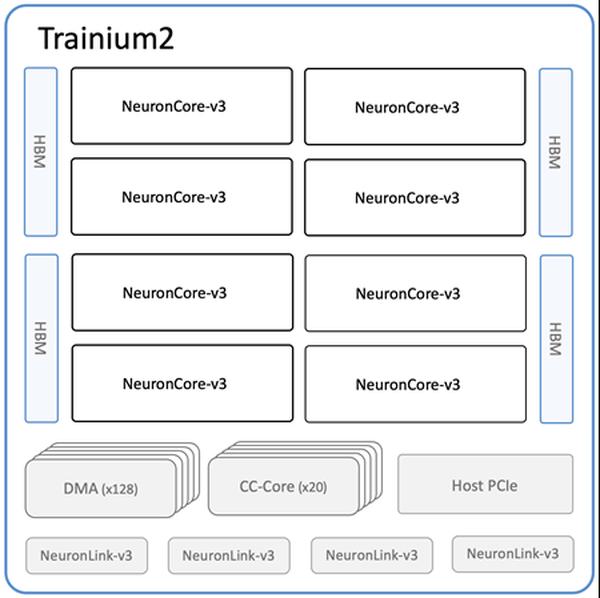
Amazon EC2 Trn2 인스턴스 및 Trn2 UltraServers, AI/ML 교육 및 추론에 사용 가능
AWS